Ich habe mir vor vielen Jahren bereits angewöhnt, alle meine Dokumente digital zu speichern. Der Vorteil liegt auf der Hand, man hat sein Büro immer dabei – auf dem Smartphone in der Hosentasche.
Viele Dokumente kommen bereits digital, Kontoauszüge, Rechnungen, … – diese kann man direkt ablegen – doch was tut man mit der trotzdem noch anfallenden Papier-Post? Dazu später mehr…
Ich nutzte zunächst einfach mein iCloud Drive für die Dateiablage. Wirklich toll am Mac ist, dass man mit der Suche im Finder auch den Inhalt von PDF-Dokumenten durchsuchen kann, WENN diese denn eine Texterkennung erhalten haben. Wenn man digitale Dokumente erhält ist das fast immer der Fall. Ebenfalls wenn Word-Dokumente als PDF abgespeichert werden. Ohne OCR [optical character recognition -> Texterkennung] kommen aber die PDF-Dokumente vom Scanner daher.
OCR auf dem Mac
Auch nutzte ich das Tool OwlOCR, welches ich mir auch gekauft habe. Das Tool ist wirklich toll, es kann auch so Dinge wie Rechtsklick auf 20 Dateien und diese dann alle in einem Rutsch mit OCR versehen. Oder in einer GUI den automatisch ermittelten OCR-Text bearbeiten, bevor dieser in das PDF eingebettet wird.
Allerdings war diese händische Nachbearbeitung immer aufwändig und mit „man muss etwas tuen“ verbunden. So suchte ich nach einer anderen Lösung. Dabei stolperte ich auch über das Problem, dass das Apple Ökosystem ziemlich abgeschottet ist und es fast unmöglich ist, externe Systeme direkt mit dem iCloud Drive arbeiten zu lassen. So war der Entschluss gefasst, vom iCloud Drive weg zu gehen, ich suchte also ein Scanner-mit-OCR-zu-Dateiablage-System.
Nextcloud
Ich hatte zuvor schon einmal Seafile ausprobiert, dort aber einen Crash erlebt. Ohne größeren Aufwand bin ich nicht in der Lage gewesen, das System wiederherzustellen. Seafile kam so für mich nicht wieder in Frage.
OwnCloud – recht bekannt – hatte ich vor vielen Jahren auch mal installiert. Beim erneuten googeln stieß ich dann aber recht schnell auf das angeblich so viel bessere Nextcloud. So gab ich dem eine Chance.
Ich installierte damals alles händisch in einem Container auf meinem heimischen Proxmox-Server. Nextcloud selbst war recht schnell ausgepackt, NGINX mit PHP-FPM installiert – auch nicht schwierig, eher Fleißarbeit. Die Nextcloud-App „Workflow OCR“ war damals recht viel Gefummel, die richtigen PHP-Pakete zu finden, den OCMemcacheAPCu, den Cron und die verschiedenen Funktion ans Laufen zu bringen.
Aber so lief es dann einige Jahre zuverlässig.
altes PHP 8.1
Nach einem der vielen Updates innerhalb von Nextcloud fiel mir dies nun auf die Füße. Es meldete mir „[…] PHP 8.1 ist ab Nextcloud 30 veraltet. Nextcloud 31 erfordert möglicherweise mindestens PHP 8.2. Bitte aktualisiere so schnell wie möglich […]„. Da war er, der Nachteil der händischen Installation.
Ich überlegt kurz, oder vielleicht auch ein bisschen länger, ob ich all die Systemabhängigkeiten wieder zusammen bekommen würde, so dass ich es auf Ubuntu 24.04 erneut installieren und einrichten könnte. Dann stellte ich aber für mich fest, dass ich das gar nicht möchte, alle X Jahre das System aktualisieren und alle Daten umziehen.
Nextcloud – AIO – All in One
So entschied ich mich, zwar alles noch einmal neu aufzusetzen, dieses mal allerdings mit der All-in-One-Version auf Dockerbasis, damit Systemabhängigkeiten direkt von Nextcloud selbst über die Docker-Container aktuell gehalten werden. Das ist im übrigen auch die von Nextcloud empfohlene Variante. Gesagt – getan.
Ich klonte eine Ubuntu 24.04 VM und installierte Docker (ein schnelles Script dazu findest Du hier). Ich machte einen Snapshot der VM (um immer wieder blanko anfangen zu können) und fing an zu experimentieren.
Die Nextcloud-App „Workflow OCR“ braucht einige Systemabhängigkeiten, diese sind aber mittlerweile gut dokumentiert. Glücklicherweise ist es über die Variable NEXTCLOUD_ADDITIONAL_APKS möglich, weitere Pakete direkt in den Dockercontainer installieren zu lassen. Welche Pakete zur Auswahl stehen, ist (zum Zeitpunkt dieses Artikels) hier zu finden. Auch weitere Nextcloud-Apps kann man mit NEXTCLOUD_STARTUP_APPS direkt konfigurieren (und die üblichen Standard-Apps auch reduzieren). So fällt bei mir die folgende docker-compose.yml heraus:
services:
nextcloud-aio-mastercontainer:
image: nextcloud/all-in-one:latest
init: true
restart: always
container_name: nextcloud-aio-mastercontainer
volumes:
- nextcloud_aio_mastercontainer:/mnt/docker-aio-config
- /var/run/docker.sock:/var/run/docker.sock:ro
network_mode: bridge
ports:
- 8080:8080
environment:
APACHE_PORT: 11000
NEXTCLOUD_STARTUP_APPS: twofactor_totp twofactor_webauthn workflow_ocr
NEXTCLOUD_ADDITIONAL_APKS: imagemagick ocrmypdf tesseract-ocr tesseract-ocr-data-deu tesseract-ocr-data-eng
NEXTCLOUD_KEEP_DISABLED_APPS: true
volumes:
nextcloud_aio_mastercontainer:
name: nextcloud_aio_mastercontainer
Über das Nextcloud AIO Interface habe ich noch folgende optionalen Container konfiguriert:
– ClamAV deaktiviert
– Collabora deaktiviert
– Fulltextsearch aktiviert
– Imaginary aktiviert
– Nextcloud Talk deaktiviert
– Nextcloud Talk Recording-server deaktiviert
– OnlyOffice deaktiviert
– Docker Socket Proxy aktiviert
– Whiteboard deaktiviert
Außerdem die Timezone Europe/Berlin konfiguriert.
Gerade das Fulltextsearch-Feature ist wirklich toll. So lassen sich die eh schon per OCR ermittelten Dateiinhalte auch über das Webinterface oder die App durchsuchen.
Des Weiteren, habe ich noch die folgenden Apps nach der Installation deaktiviert: Dashboard, Photos und User status.
Die ersten Fehlermeldungen kann man hiermit beheben:
docker exec --user www-data -it nextcloud-aio-nextcloud php occ maintenance:repair --include-expensive
docker exec --user www-data nextcloud-aio-nextcloud php occ config:system:set default_phone_region --value="DE"NGINX-Proxy
Ich betreibe meine Nextcloud hinter einem NGINX-Proxy, die config dazu sieht so aus:
server {
listen 443 ssl http2;
listen [::]:443 ssl http2;
server_name c.heg.ge;
ssl_certificate /path/to/rsa-cert/fullchain.pem;
ssl_certificate_key /path/to/rsa-cert/privkey.pem;
ssl_certificate /path/to/ecc-cert/fullchain.pem;
ssl_certificate_key /path/to/ecc-cert/privkey.pem;
proxy_buffering off;
location / {
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Port $server_port;
proxy_set_header X-Forwarded-Scheme $scheme;
proxy_set_header X-Forwarded-Proto $scheme;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header Accept-Encoding "";
proxy_set_header Host $host;
proxy_pass http://<IP>:11000;
proxy_http_version 1.1;
proxy_hide_header Upgrade;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection $connection_upgrade;
client_body_buffer_size 512k;
proxy_read_timeout 86400s;
client_max_body_size 0;
}
more_set_headers "Strict-Transport-Security: max-age=31536000; includeSubDomains; preload";
more_set_headers "X-Frame-Options: SAMEORIGIN";
more_set_headers "X-Content-Type-Options: nosniff";
more_set_headers "Referrer-Policy: same-origin";
more_set_headers "X-XSS-Protection: 1; mode=block";
}
map $http_upgrade $connection_upgrade {
default upgrade;
'' close;
}Der Trick mit dem anderen User
Leider ist es so, dass „Workflow OCR“ so trigger nutzt wie „Datei erstellt“ oder „Schlagwort zugewiesen“. Aber alle neu erstellten PDF-Dokumente will ich nicht immer mit OCR behandeln. Auch will ich nicht jeder Datei, die OCR bekommen soll, vorher einen Tag zuweisen.
Also erstellte ich mir einen separaten Benutzer namens „OCR“. Jener hat den folgenden Workflow:
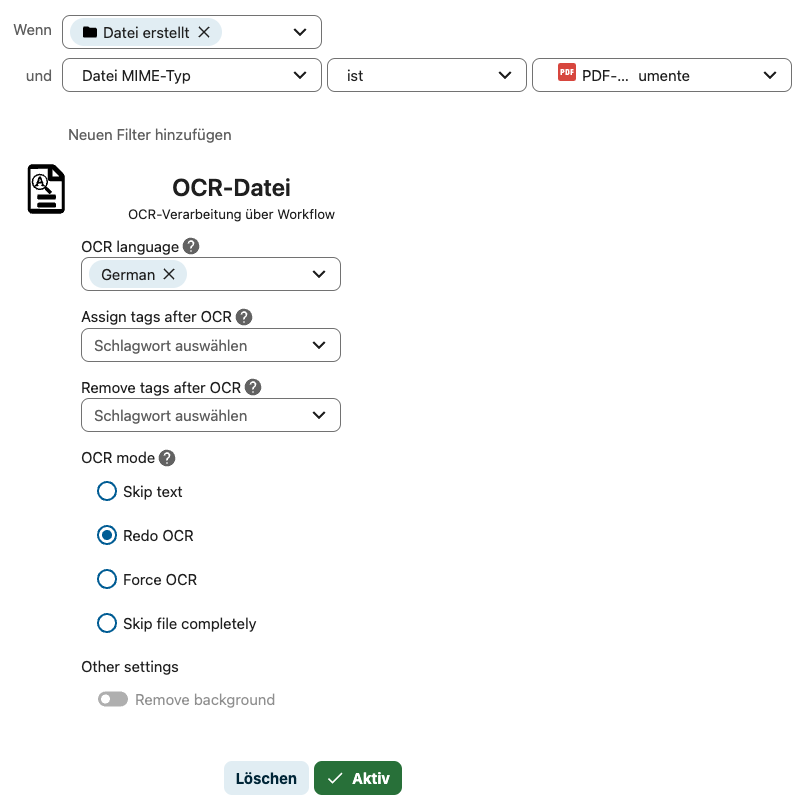
Dann teilte ich jeden Ordner, in welchem neu erstellte PDF-Dokumente automatisch OCR bekommen sollen, mit dem User „OCR“ (mit „Kann bearbeiten“-Rechten). So wird OCR nur auf diese geteilten Ordner angewendet.
Die Anbindung des Scanners
Wie bekomme ich denn nun die Dokumente des Scanners in die Nextcloud?
Dazu habe ich einen weiteren Server eingerichtet, auf diesem Samba installiert und konfiguriert und dort eine Freigabe eingerichtet. Der Scanner (eigentlich ein Multifunktions-Drucker) scannt nun auf diese SMB-Freigabe. Außerdem ist auf dem Server das Paket nextcloud-desktop-cmd installiert, welches nextcloudcmd bereitstellt (ja, das naming ist großartig), ein CLI-Tool um Nextcloud-Daten zu syncen. Mit diesem und einem Cron-Job wird dann alle 2 Minuten die SMB-Freigabe mit der Nextcloud syncronisiert:
/usr/bin/nextcloudcmd -s \
-u '<OCR-USERNAME>' -p '<PASSWORT>' \
/pfad/zum/lokalen/ordner/ \
https://<DOMAIN>/remote.php/webdav/<REMOTE-ORDNER-NAME>/So landen dann die Dokumente als PDF ohne OCR auf der SMB-Freigabe, werden von dem Nextcloud-CLI-Tool in die Nextcloud gesynct, dort wird dann das „Datei erstellt“-Event getriggert, welches das „Workflow OCR“ triggert, welches das PDF-Dokument mit OCR versieht.
Benachrichtigung
Ich habe noch unter Profilbild (oben rechts) -> „Persönliche Einstellungen“ -> „Benachrichtigungen“ den Punkt „Eine Datei oder ein Ordner wurde geändert“ mit „Push“ aktiviert. Das sorgt dann für eine Benachrichtigung, nachdem der OCR-Benutzer das OCR dem PDF-Dokument hinzugefügt hat. Da der Cron auf dem SMB-Server nur alle 2 Minuten und der Cron auf der Nextcloud, welcher die Verarbeitung anstößt, nur alle 5 Minuten läuft, bekomme ich so eine Info, sobald ein Dokument fertig ist. So kann ich es anschließend umsortieren oder anderweitig verarbeiten.
There’s one more thing
Was mache ich denn, wenn ich an einem fremden Multifunktions-Gerät bin, und von dort einen Scan in meine Nextcloud übertragen will?
Was mache ich, wenn ich die per E-Mail versendeten Dokumente (wie z.B. Rechnungen) direkt in meine Nextcloud abgelegt haben will?
Richtig, ich erstelle eine inbound E-Mail-Adresse, an die ich abhängig vom Absender, E-Mails weiterleiten kann. Von dort werden dann die Dateianhänge in meine Nextcloud importiert.
Mailgun
Wie ist das technisch umgesetzt?
Die E-Mails landen zunächst beim E-Mail-Anbieter Mailgun. Dieser hat ein kostenloses Freikontingent pro Monat, welches ich bei weitem nicht überschreite. Hier ist unter dem Punkt „Receiving“ eine Route konfiguriert, welche einfach die Option „Store and notify“ aktiviert und als Ziel eine Adresse meines Servers gesetzt hat.
Für dieses Ziel habe ich einen weiteren Server eingerichtet. Hier läuft ein NGINX, welcher mithilfe von PHP den POST-Request von Mailgun entgegen nimmt und verarbeitet. Das PHP-Script entnimmt den JSON-Daten die Abruf-URLs der E-Mail-Anhänge, lädt diese herunter und speichert sie auf der Festplatte. Anschließend werden sie wieder mit einem Cron-Job und dem nextcloudcmd an die Nextcloud übertragen.
# config.php
<?php
define('MAILGUN_USER', '<USER>');
define('MAILGUN_PASS', '<PASSWORT>');#index.php
<?php
include_once '../config.php';
function get_url_content($url) {
$options = array(
CURLOPT_RETURNTRANSFER => true,
CURLOPT_HEADER => false,
CURLOPT_FOLLOWLOCATION => true,
CURLOPT_MAXREDIRS => 10,
CURLOPT_ENCODING => "",
CURLOPT_USERAGENT => "",
CURLOPT_AUTOREFERER => true,
CURLOPT_CONNECTTIMEOUT => 10,
CURLOPT_TIMEOUT => 10,
CURLOPT_IPRESOLVE => CURL_IPRESOLVE_V4,
CURLOPT_USERPWD => MAILGUN_USER.':'.MAILGUN_PASS,
);
$ch = curl_init($url);
curl_setopt_array($ch, $options);
$content = curl_exec($ch);
curl_close($ch);
return $content;
}
$allowed_mime_types = [
'application/pdf' => 'pdf',
'image/jpeg' => 'jpg',
'image/png' => 'png',
'image/tiff' => 'tiff',
];
if(isset($_REQUEST['attachments'])){
$attachments = json_decode($_REQUEST['attachments'], true);
foreach ($attachments as $attachment){
$hash = substr(str_shuffle(MD5(microtime())), 0, 6);
$filename = '../data/'.date_create()->format('Y-m-d_H-i-s').'__'.$hash.'__';
if(array_key_exists($attachment['content-type'], $allowed_mime_types)){
$filename .= $attachment['name'].'.'.$allowed_mime_types[$attachment['content-type']];
file_put_contents($filename, get_url_content($attachment['url']));
} else {
$filename .= 'invalid_mime-type.txt';
file_put_contents($filename, var_dump_ret($attachment));
}
}
}Mir ist hierbei durchaus bewusst, dass der Dateiname der Datei böse sein könnte, und dass man diesen ggf. nicht wieder übernehmen sollte. Ich habe mich hier für eine Zwischenlösung entschieden, indem der Dateiname vorne mit Datum und Hash angereichert und hinten mit der Dateiendung basierend auf dem echten MIME-Type versehen wird. Außerdem werden generell nur bestimme MIME-Types zugelassen.
There’s one more one more thing
Als weitere kleines Gadget habe ich folgendes umgesetzt:
Bei dem kostenlosen E-Mail-Anbieter web.de kann man zusätzlich zu seiner E-Mail-Adresse auch die kostenlose Funktion Briefankündigung (eigentlich ein Service der Deutschen Post) buchen. Der Vorteil gegenüber dem Service von der Deutschen Post selber ist, dass die Ankündigung bei web.de per E-Mail statt per App kommt (aber dennoch von der Deutschen Post). Und – ihr ahnt es sicherlich schon – auch diese E-Mails werden an meine Inbound-E-Mail-Adresse weitergeleitet und die Scans der Umschläge landen in der Nextcloud. Hier habe ich für jedes Familienmitglied einen eigenen web.de-Account erstellt und den Service aktiviert, sonst wäre eine Benachrichtigung für andere Personen als man selbst von der Post nicht möglich.
So ein Scan sieht dann z.B. so aus (Adresse von mir geschwärzt):

Zukunftsmusik
Eine weitere Idee wäre es noch, eine Push-Notification an mein Smartphone zu senden, in welcher das Foto des Briefumschlages enthalten ist. Technisch machbar sind solche Push-nachrichten über mein Smarthome-System HomeAssistant. Allerdings hab ich aktuell noch keine Lösung dafür, wie ich mein HomeAssistant über einen neuen Brief benachrichtigen soll. Wenn ich mal Zeit habe, setze ich das vielleicht noch um …